А вы знаете, что некоторые буквы алфавита встречаются в словах чаще остальных...Причем частота употребляемости гласных букв в языке выше, чем согласных.
Какие буквы русского алфавита чаще или реже всего встречаются в словах, используемых для написания текста?
Выявлением и исследованием общих закономерностей занимается статистика. С помощью этого научного направления можно ответить на поставленный выше вопрос, сосчитав количество каждой из букв русского алфавита, применяемых слов, выбрав отрывок из произведений различных авторов. Для собственного интереса и ради занятия от скуки каждый может проделать это самостоятельно. Я же сошлюсь на статистику уже проведенного исследования...

Русский алфавит кириллический. За время своего существования он пережил несколько реформ, в результате которых сложилась современная русская азбучная система, включающая 33 буквы.

о — 9.28%
а — 8.66%
е — 8.10%
и — 7.45%
н — 6.35%
т — 6.30%
р — 5.53%
с — 5.45%
л — 4.32%
в — 4.19%
к — 3.47%
п — 3.35%
м — 3.29%
у — 2.90%
д — 2.56%
я — 2.22%
ы — 2.11%
ь — 1.90%
з — 1.81%
б — 1.51%
г — 1.41%
й — 1.31%
ч — 1.27%
ю — 1.03%
х — 0.92%
ж — 0.78%
ш — 0.77%
ц — 0.52%
щ — 0.49%
ф — 0.40%
э — 0.17%
ъ — 0.04%
Русская буква, имеющая наибольшую частотность в использовании - это гласная «О », как здесь уже справедливо предположили. Есть и характерные примеры, наподобие «ОбОрОнОспОсОбнОсти » (7 штук в одном слове и ничего экзотического или удивительного; очень привычно для русского языка). Высокая популярность буквы «О» во многом объясняется таким грамматическим явлением, как полногласие. То есть, «холод» вместо «хлад» и «мороз» вместо «мраз».
А в самом начале слов чаще всего встречается согласная буква «П ». Это лидерство также уверенно и безоговорочно. Скорее всего, объяснение даёт большое количество приставок на букву «П»: пере-, пре-, пред-, при-, про- и другие.
Частота использования букв основа криптоанализа.
Самой распространённой буквой в алфавите русского языка можно смело назвать «о». Не «а», хотя все дети учат первые слова именно с этой буквой: «мама», «папа» или «дай». Не «и», хотя может показаться, что мы часто употребляем ее как соединительный союз.
Как показывают данные, именно буква «о» имеет частотность, превышающую 0, 1%, по сравнению с другими гласными буквами алфавита, у которых частотность составляет, например, 0,07-0,08%, это немало
Среди согласных на первом месте стоит буква «н».
Такие данные получают путем анализа частотности в НКРЯ – Национальном корпусе русского языка, по специальной формуле. НКРЯ – это электронный архив письменных и устных текстов, который состоит примерно из 230 миллионов словоупотреблений.
Рассматривая самую популярную букву нашего алфавита, стоит упомянуть об интересном явлении, которое называется «тавтограмма». Это своеобразная литературная разминка, где нужно составить рассказ или стихотворение, начинающееся с одной и той же буквы. Кстати, буква, с которой начинается больше всего слов русского языка (не путайте с частотностью употребления) - это «п», но среди гласных несомненное лидерство принадлежит нашему сегодняшнему фавориту.
«Одиноко. Очень. Осколки обаяния осыпались осенним однообразием. Олимп остался отдаленной отдушиной. Очень отдаленной. Остались обиды, опрометчивые определения оттаявшей оттепели, обусловленные огнем осязания. Остальное оказалось отрицательным, отторгнутым, обманутым обществом. Отпрыски осени оступились, облетели остатками озерных очей. Одни окна остались открытыми. Обозленные отпечатки отдельных омонимов омрачены отвергнутыми одеждами олицетворения. Оранжевые оттенки облепихи очерчены огромным отражением одиночества. Остальное – окостенение, оцепенение обреченности. Острова обросли обетами от очерков о определенности. Остывающие обрезки ольхи образовали одноименные окружности, обусловленные охрипшими окриками. Официальное обернулось отражением общего, отменив отрицательные определенности. Осевшие образы обидчиво объясняли осеннюю околесицу, обзывая обратное обманом. Отроки отчаянно обрисовывали очарованную осень, отрицая объективное отношение… Осень облетала оранжевыми осколками облепихи, оставляя осточертевшие оспаривания одиноким ответам…»
Забавно, правда? Не такая уж и чепуха выходит:)
Кстати, в английском языке самой распространенной буквой является “е". А согласной – “t"
Ну, и тавтограмма на английском языке:
Minerva-like majestic Mary moves.
Law, Latin, Liberty, learned Lucy loves.
Eliza"s elegance each eye espies.
Serenely silent Susan"s smiles surprise.
From fops, fools, flattery, fairest Fanny flies.
so dominating and happy individuality that Youth is drawn to him as is a fly to a sugar bowl. (см. ).
Весьма немногие могут заметить в данном тексте что-нибудь необычное, даже прочитав гораздо больший отрывок из этой книги, пока их не попросят очень внимательно его изучить. И даже после этого большинство не в состоянии заметить эту уникальную особенность.
Частоты встречаемости букв в других языках, кроме английского
Для любого языка с алфавитной записью шифр простой замены вскрывается описанным выше методом: подсчетом частот встречаемости знаков с последующим использованием контекстной информации языка. Ясно, что для этого криптоаналитику необходимо по крайней мере неплохо знать язык, хотя в случае шифра простой замены ему не обязательно говорить на нем свободно. Не менее очевидно, что подсчет частот встречаемости знаков в типичном отрывке текста будет для разных языков давать разные результаты, хотя для языков с общей основой, такой как латынь, это отличие будет меньше, чем для языков различного происхождения. Не во всех языках используется 26-буквенный алфавит; в некоторых букв меньше - в итальянском обычно употребляются только 22; в других, например в русском, букв больше, а в третьих (например, в китайском), алфавита вообще нет. Поскольку итальянцы обычно не используют буквы K, W и Y, то их частоты полагают равными нулю, но если в итальянском тексте упоминается Нью-Йорк (New York), то и эти буквы в нем встретятся. Во французском и немецком языках необходимо различать гласные с различными диакритическими знаками (акцентами и умляутами), но ради упрощения приведенных ниже таблиц все формы одной и той же буквы подсчитывались вместе. Так, для французского языка частоты букв E, E, E и E учтены вместе в суммарной частоте буквы E. Числа также исключены из подсчета, кроме тех, которые записаны словами; все неалфавитные символы (пробел, запятая, точка, кавычки, точка с запятой и т.д.) учтены в графе "другие". Заглавные и строчные буквы считались одинаковыми. В таблице 2.6 приведены (с учетом приведенных оговорок) частоты встречаемости букв для четырех европейских языков в расчете на 1000 знаков. Для удобства мы повторяем здесь таблицу частот встречаемости букв английского языка.
Статистический анализ этих подсчетов показывает, что если речь идет о частотах встречаемости одиночных знаков, то английский, французский, немецкий и, в меньшей степени, итальянский языки довольно близки, а их родство с валлийским заметно слабее. Частично это объясняется тем, что в валлийском языке Y - очень частая буква: она является гласной и имеет два
различных произношения. В английском языке она встречается гораздо реже, а в других языках и вовсе очень редка. Подсчеты также показывают, что букву N можно назвать "наиболее постоянной буквой", поскольку во всех пяти языках частота ее встречаемости практически одинакова - от 6% до 7% всех букв латинского алфавита. Объяснение сути статистических тестов, применяемых обычно для сравнения частот, подобных приведенным здесь, можно найти в ; дополнительный комментарий содержится в приложении M20.
Таблица 2.6
английский |
французский |
немецкий |
итальянский |
валлийский |
||
Сколько знаков необходимо для дешифрования простой замены?
Выше в примере 2.2 у нас было в наличии 265 знаков, и дешифрование простой замены оказалось не очень трудным делом. Смогли бы мы справиться с ним столь же легко, будь у нас, к примеру, 120 знаков? И вообще (этот вопрос уже ставился нами ранее), каково минимальное число знаков, которое, скорее всего, окажется достаточным для криптоаналитика при дешифровании подобного шифра? На данный вопрос отвечает теория информации: оценку этого числа дает формула, зависящая от частот одиночных знаков или полиграфов языка. В описано применение этой формулы для конкретного приложения. Если использовать только частоты отдельных знаков, то для шифра простой замены, возможно, окажется достаточно 200 знаков, но использование диграфов (таких как ON, IN или AT) или триграфов (таких как THE или AND) чрезвычайно усиливает возможности дешифрования. Полагают, что в этом случае может оказаться достаточно всего 50 или 60 знаков.
Задача 2.1 Перехвачен шифрованный текст на английском языке длиной 202 знака.
Известно, что использован шифр простой замены, и что пробелы в открытом тексте заменены на букву Z, а все остальные знаки препинания опущены. Есть основания полагать, что автор предпочитает использовать устаревшую форму местоимения "thy" вместо местоимения "your". Дешифруйте текст.
VHEOC WZIHC BUUCW HDWZB IRWDH TDOZH VIHVI YBWIU HQOWU HUFWH ZOXBI LHTBI LWDHG DBUWE HVIRH FVXBI LHGDB UHZOX WEHOI HIODH VCCHU FPHQB WUPHI ODHGB UHEFV CCHCN DWHBU HSVYJ HUOHY VIYWC HFVCT HVHCB IWHIO DHVCC HUFPH UWVDE HGVEF HONUH VHGOD RHOTH BU
Пример 2.2 показывает, что хотя шифры простой замены вскрыть гораздо сложнее, чем шифры Юлия Цезаря, всё же их слишком легко дешифровать, и поэтому применение их не имеет большого смысла. Для вскрытия такого шифра криптоаналитику всего лишь необходимо иметь достаточный объем шифрованного текста (это соответствует первой ситуации, упомянутой в предыдущей главе). Если ему известен также и соответствующий открытый текст (как во второй ситуации), его задача становится просто тривиальной, если только "сообщение" не состоит из очень малого числа различных букв. В третьей ситуации, когда у криптоаналитика есть возможность подобрать текст для зашифрования, ему достаточно задать такое "сообщение":
ABCDEFGHIJKLMNOPQRSTUVWXYZ
и его работа на этом завершена.
Несведущему читателю может показаться, что поскольку число различных вариантов превосходит 1026 (то есть сто миллионов миллионов миллионов миллионов), то задача вскрытия шифра простой замены только по шифрованному тексту (для решения которой методом "грубой силы", как уже отмечалось ранее, компьютеру потребуются миллионы лет для перебора всех вариантов) является невыполнимой. Однако мы только что видели, как это можно сделать вручную в течение часа, если использовать известные неравновероятные частоты встречаемости знаков и грамматические правила английского, или любого другого языка, на котором составлено сообщение, вкупе с любой доступной контекстной информацией. Из этого следует один очень важный урок:
крайне опасно судить о стойкости системы шифрования только по времени, которое необходимо затратить самому быстрому компьютеру, какой только можно вообразить, для дешифрования методом "грубой силы".
Итак, на следующем этапе мы рассмотрим способы повышения стойкости этих простых методов шифрования. Это сделано в следующей главе.

Пирог «Пусть едят пирожные»
Ингредиенты:
2 унции молотого миндаля,
6 унций самоподнимающейся муки,
2 чайные ложки пекарного порошка,
4 унции светлого сахара «мусковадо»,
150 мл кукурузного масла,
200–250 мл соевого молока,
цедра двух невощеных лимонов,
сок из двух лимонов,
1 столовая ложка душистой воды из цветков апельсинного дерева,
1 чайная ложка натурального экстракта ванили.
Предварительно нагрейте духовку до 190 градусов или меньше, если духовка с поддувом.
Смажьте жиром форму для пирога. Лучше всего глубокая шестидюймовая форма, но сойдет любая.
Всыпьте муку и пекарный порошок в миску, потом добавьте сахар. Всыпьте, помешивая, молотый миндаль и лимонную цедру. Добавьте масло и молоко. Чем меньше жидкости, тем больше блюдо будет похоже на пирог, а не на пудинг. Для этого пирога не нужно отмерять жидкости со стопроцентной точностью.
Теперь добавьте лимонный сок и тщательно размешайте. Добавьте цветочную воду и экстракт ванили, перемешайте еще раз. Результат должен выглядеть как густое бездрожжевое тесто.
Влейте его в форму и поставьте в духовку минут на сорок. Корочка должна быть коричневой, а начинка очень мягкой. Выложите из формы, охладите и украсьте свежими листьями мяты и земляникой.
| Буква | Частота | Буква | Частота | Буква | Частота |
| а | 0,075 | К | 0,034 | Ф | 0,002 |
| б | 0,017 | л | 0,042 | X | 0,011 |
| в | 0,046 | м | 0,031 | ц | 0,005 |
| г | 0,016 | и | 0,065 | ч | 0,015 |
| д | 0,030 | о | 0,110 | ш | 0,007 |
| е, ё | 0,087 | II | 0,028 | щ | 0,004 |
| ж | 0,009 | р | 0,048 | ь, ъ | 0,017 |
| 0,018 | с | 0,055 | ы | 0,019 | |
| и | 0,075 | т | 0,065 | э | 0,003 |
| и | 0,012 | у | 0,025 | ю | 0,022 |
| я | 0,022 |
Из таблицы следует, что на каждую тысячу букв в среднем приходится 75 букв а, 17 букв б, 46 букв в и т. д.
Получив шифрованное письмо, вам придется лишь подсчитать частоты появления в нем различных секретных значков и сопоставить их с теми частотами, что в таблице. Так, если на тысячу восемьсот букв письма окажется 135 «треугольников», то это означает, что данный значок
А вот еще один эксперимент – специально для любителей «счастливых» билетов. (Как известно, «счастливым» считается такой трамвайный, автобусный, троллейбусный билет, у которого сумма первых трех цифр равна сумме трех последних). В теории вероятностей существует формула, в соответствии с которой на каждые 100 билетов в среднем 5–6 должны оказаться «счастливыми». И если не полениться собрать необходимую пачку в сто билетов, то можно легко в этом убедиться.
«Обязательность» случая была давно подмечена предприимчивыми людьми.
В чем смысл игры для хозяина рулетки? Главный «секрет производства» здесь в том, что выпадение цифры 0 – ее называют «зеро» – всегда в пользу хозяина, независимо от того, на «красное» или «черное» поставил игрок свои деньги. За счет этой единственной цифры и существует хозяин рулетки. И не только он. Целое государство Монако живет за счет доходов знаменитого игорного дома в Монте-Карло, где идет крупная игра в рулетку. Трудно придумать более яркий пример использования закономерностей случайных явлений: выход «зеро» определенное число раз столь же обязателен, как, скажем, падение подброшенного камня на землю, хотя каждая отдельная цифра появляется случайно и никакими силами заранее угадана быть не может.
И все же Смок Беллью, герой повести Джека Лондона, если вы помните, научился почти безошибочно предугадывать, где остановится шарик. Как ему это удавалось делать?
Джек Лондон раскрывает секрет своего любимого героя. Наблюдая за игрой, Смок подметил, что колесо останавливалось не как попало – этого, казалось бы, следовало ожидать, – а по определенным правилам. «Случайно я дважды отметил, где остановился шарик, когда вначале против него был номер девять. Оба раза выиграл двадцать шестой». Столь странное поведение колеса объяснялось тем, что рулетка стояла недалеко от печки: ее деревянное колесо рассохлось и покоробилось. Смоку удалось уловить скрытую от других закономерность поведения колеса.
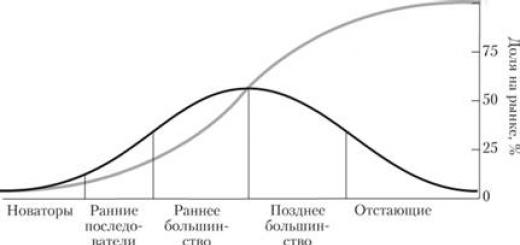
Стоит ли, однако, утверждать, что можно выявить систему у любых – всех проявлений случая? Попробуйте, например, установить общие закономерности изменения моды, формы одежды, которая, безусловно, относится к случайным явлениям. На рис. 8.1 показаны колебания мод женской одежды почти за 50 лет XX века. Срок вполне достаточный, чтобы найти хоть какие-нибудь основательные регулярности. Однако их нет. Все – и форма шляпок, и силуэт платья – меняются «как попало». Остается незыблемым лишь общий принцип: «новое – это прочно забытое старое». Предпринимавшиеся попытки связать капризы моды с мировыми катаклизмами – войнами, экономическими кризисами, даже с солнечной активностью – ни к чему не привели.
Рис. 8.1. Динамика дамской моды
Возможность установления определенного порядка, закономерностей в случайных явлениях, как правило, связана с наличием в них так называемой «устойчивой частоты»: появление интересующего нас события, например рождение младенца мужского пола, при многократном повторении происходит в одинаковой доле от общего числа рождений.
Поисками закономерностей в случайных явлениях занимается специальная, хорошо разработанная в наши дни наука – статистика. Именно статистика после многих наблюдений над случаем делает заключение о том, устойчива ли частота его появления. Когда такую устойчивость удается обнаружить, статистики говорят о наличии статистического ансамбля.
Изучением закономерностей в случайных явлениях занимается теория вероятностей . Познакомимся с основами этой науки.
Как и многие другие понятия, слово «вероятность» с его производным «вероятно» входит в нашу жизнь с детства. Мы говорим: вероятно, вечером будет дождь; я, вероятно, простудился и т. п.
« Вероятно» в этих привычных фразах означает «возможно» – этим словом субъективно оценивается возможность наступления интересующего нас случайного события в будущем. Если же появляется необходимость показать степень этой возможности, мы уточняем: «весьма вероятно», «маловероятно», «совершенно невероятно». Более четкие градации, чем «много» и «мало», в обиходном языке не предусмотрены. Между тем жизненные задачи требуют оценки вероятности более конкретной, чем «много» или «мало». Сегодня на морском транспорте сказать: вероятно, будет (или не будет) происшествие – это значит не сказать почти ничего. Степень возможности появления будущего случайного события – вероятность – должна быть оценена объективно точно, определенным числом.
Самый старый, так называемый классический способ измерения вероятности – по частоте наступления интересующего нас события. Это можно сделать весьма просто: прийти в тир, выстрелить все 100 раз и сосчитать число попаданий в мишень. Доля, которую это число составит от общего числа выстрелов, и есть частота попаданий. Скажем, попали 70 раз – частота равна 0,7, или семидесяти процентам. Вот эта самая частота и принимается за вероятность.
Но что значит «принимается»? Почему не сказать просто: вероятность – это и есть частота интересующего нас события? По той же самой причине, по которой мы различаем вчерашнюю сводку погоды и прогноз на завтра. Частота -это результат события, которое уже произошло, вероятность – предсказание того, что должно случиться в будущем. Сказать: «Вероятность попадания 70 процентов» – значит предположить, что при очередной стрельбе 70 пуль из ста попадут в мишень. Это предположение мы делаем в уверенности, что соотношение шансов попасть – не попасть, которое определилось во время уже состоявшейся стрельбы, сохранится и на будущее. При этом, разумеется, предполагается, что условия стрельбы: оружие, расстояние до мишени, размеры мишени и т. д. – останутся неизменными.
Применительно к бизнесу это означает, что если при определенных условиях в прошлом мы получали, на каждые 100 рублей 30 рублей прибыли, то при повторении ситуации в будущем сохранится и прибыль.
Откуда, однако, у нас берется уверенность, что «дальше будет, как раньше»? К этому нас подводит весь многовековой коллективный опыт человечества. Когда народ говорит, например, «У семи нянек дитя без глаза», «Тише едешь – дальше будешь» или утверждается, что «бутерброд падает маслом вниз», – это не только о прошлом, но и о будущем.
Если в течение многих лет люди наблюдают, как из 100 куриных яиц появляется примерно поровну петушков и курочек, то нет основания не верить, что и на следующий год шансы появления петушка останутся прежними. В слове «вероятно» явственно прослушивается «надеюсь». Это дало основание магистру философии Вильнюсского университета Сигизмунду Ревковскому – первому, кто в 1829– 1830 годах стал преподавать в России (тогдашней) теорию вероятностей, – определить вероятность как «меру надежды».
Итак, для того чтобы рассчитать вероятность во многих распространенных жизненных задачах, достаточно произвести весьма элементарное арифметическое вычисление – разделить число случаев, благоприятствующих интересующему нас событию, на общее число всех возможных случаев.
Важно отметить, что чем больше опытов проведено при определении частоты, тем точнее, объективнее получается вероятность. Это проявление одного из важнейших законов, управляющих случаем, – так называемого закона больших чисел.
Классический способ определения вероятностей и его формула и сегодня находят широкое применение. Если нам, скажем, известно, что среди тридцати экзаменационных билетов три очень трудных, то можно быстро прикинуть вероятность вытащить трудный билет, как = 0,1, или 10 процентов. И если бы можно было таким простым способом рассчитывать вероятности во всех случаях, то учебники по теории вероятностей (а заодно и данная глава) были бы много тоньше. К большому сожалению, столь просто рассчитывать вероятность удается далеко не всегда.
Представьте себе, что вы получили перед какой-либо жеребьевкой весьма обнадеживающую информацию: организатор кладет плохие билеты не как попало, а снизу, видно стараясь, чтобы они оказались подальше от испытуемых. Это, конечно, хорошо: стоит теперь вытянуть билет сверху – и вероятность заполучить выгодный номер резко увеличится. Но вот какой она станет? Узнать это с помощью классической формулы невозможно. Формула применима лишь тогда, когда все рассматриваемые случаи равновозможны – любой билет должен иметь одинаковые шансы попасть в руки испытуемого. Стоит исключить эту равновозможность, и классическая формула перестает работать. Следовательно, правильно эту формулу записать так:
Откуда же мы знаем, равновозможны случаи или нет? На этот вопрос отвечает опыт. Причем опыт, который не обязательно ставить. Бывает, вполне достаточно провести его мысленно. Допустим, вы собрались сыграть с товарищем в шахматы. Кому играть белыми, должен решить жребий. Ваш партнер в одной руке зажимает белую фигуру, в другой – черную. Какова вероятность, что вы будете играть белыми? Каждый из нас, не задумываясь, назовет 50 процентов. Но почему? Это результат мысленного опыта: мы инстинктивно оцениваем шансы отгадать любую фигурку как равновероятные, и поскольку белых фигур ровно половина, то это и будет интересующая нас вероятность.
Вот еще один пример. Многим читателям, видимо, доводилось слышать о такой дикой игре армейского захолустья царской России. В барабан многозарядного револьвера закладывается лишь один патрон, после чего барабан несколько раз проворачивается. Затем участники игры по очереди приставляют револьвер к виску и нажимают на спуск. Так вот, для того чтобы сказать, чему равна при этом вероятность проигрыша, явно нет необходимости ставить эксперимент. Так же как и при отгадывании шахматной фигуры, равновозможность шансов здесь очевидна из соображения о симметрии возможных исходов. И вероятность проигрыша – получения пули – для того, кто стреляет первым, в расчете на 5 патронов равна:
Вполне можно ограничиться мысленным экспериментом и там, где равновозможность шансов очевидна из геометрического представления задачи. Скажем, в офисе проложен телефонный кабель длиной 60 метров, из которых 3 метра приходится на труднодоступное место. Спрашивается, какова вероятность в случае выхода кабеля из строя, что повреждение случится именно на труднодоступном участке?
Такую вероятность иногда называют геометрической – ведь она получена путем сопоставления длин двух отрезков. И соображение о равновозможности шансов (уверенность в том, что появление неисправности возможно в любом месте кабеля) в этом случае исходит из наглядных, геометрических представлений.
Интуитивное определение вероятности, выработанное человеком и ходе многовековой эволюции, не раз выручало его в сложных ситуациях. Принимая решение «что лучше», «что быстрее», «какова мера опасности», люди, сами того не ведая, часто основывают свой выбор на интуитивной вероятной оценке. «Лучше поездом, чем самолетом», «Поеду-ка я трамваем, автобуса не дождаться», «Сегодня стоит надеть плащ» – во всех этих решениях явно просматривается учет возможности случая.
С интуитивным определением вероятности тесно связан так называемый принцип практической уверенности. Принцип этот можно сформулировать так: «Если вероятность события мала, то следует считать, что в однократном опыте – в данном конкретном случае – это событие не произойдет. И наоборот – при большой вероятности событие следует ожидать».
В повседневной жизни мы широко, сами то не подозревая, пользуемся этим важным принципом. Скажем, собираясь лететь в отпуск самолетом, мы уверены в том, что нас доставят на места в целости и сохранности: не пишем завещание, даем телеграмму с просьбой встретить т. п. Тем самым мы интуитивно принимаем, что вероятность аварии самолета равна нулю – событие невозможное, хотя эта вероятность всегда имеет некоторое, правда весьма небольшое, но все же отличное от нуля значение. Вероятность же нашей доставки до места соответственно но принимается равной единице – событие это считается достоверным.
Оценивая практическую невозможность или достоверность события и принимая на этой основе решение, мы, однако, далеко не всегда связываем свой выбор с предельными, крайним значениями вероятности. Величина вероятности, которая нас практически устраивает, зависит от того, какова важность последствий принятого нами решения. Решение надеть плащ может быть принято и в том случае, если вероятность дождя, скажем, 70–80 %. Но вряд ли мы решимся прыгнуть с парашютом, узнав, что у него такая же (70–80 %) надежность.
Итак, вероятность – это степень возможности появления будущего случайного события Руководствуясь этим определением, решим несколько примеров.